文章目录
- 前言
- 内容
- 代码应当易于理解
- 命名
- 注释
- 格式
- 循环和逻辑
- 设计函数
- 设计类
- 其它(编程规范、静态检查工具)
- 重构
前言
在软件开发领域,写好代码是至关重要的一环。不论是在学校学习的学生,刚刚毕业的应届生,还是刚步入企业的新人,很多人都存在一个普遍的问题:只关注实现功能,而忽略了代码质量及可维护性。然而,良好的代码质量是软件工程实践中的重中之重,它是通过经验总结出来的宝贵财富。
在学习过程中,写好代码不仅仅是为了通过考试,更是为了培养良好的编程习惯。而在面试中,写代码已经成为了必不可少的环节,无论是在线笔试还是现场手撕代码。在这个过程中,评价标准不仅仅是代码的逻辑是否正确,更包括代码的可读性和优雅程度。
即使你的代码在逻辑上是正确的,通过了所有的测试用例,但如果代码的结构混乱、命名不规范,缺乏注释,那么也会给面试官留下不好的印象,成为减分项。相反,如果你的代码不仅逻辑正确,而且结构清晰,注释充分,命名规范,那么必然会给人留下深刻的印象,为你的技术水平加分不少。
因此,写好代码不仅仅是技术能力的体现,更是对工程素养和专业态度的展示。在日常学习和工作中,我们应该不断提升自己的代码质量,注重编程规范,追求优雅的代码风格,这样才能在竞争激烈的软件行业中脱颖而出,实现个人的职业发展目标
内容
代码应当易于理解
编写易于理解的代码的重要性
代码的编写对象不仅仅是执行它的计算机,尽管它确实是为了机器运行而设计的。然而,代码的可读性对于其他开发者来说同样重要,包括未来的您自己。在编写代码时,我们应该始终牢记这一点:代码是为了让人阅读的。
注释和命名的重要性
避免仅定义变量如ABCD而不提供任何注释,这会导致读者难以理解每个变量的具体含义。良好的命名和注释是提高代码可读性的关键。此外,代码的格式、循环逻辑的处理等,都应遵循一定的技巧和规则。
遵循编码规范
每个大型企业都有自己的编码规范,这些规范通常是基于通用的编程标准,如C、Java或Python的。这些规范会在您编写代码时提供即时反馈,指出哪些部分不符合标准,并指导您进行相应的修改。
严格的格式要求
一些公司对代码格式有严格的要求,例如,代码行的长度限制、使用Tab还是空格进行缩进等。不遵守这些规定可能会导致严重的后果,比如在技术考核中得零分。
代码质量的评估
代码的质量评估不仅包括代码本身的编写质量,还包括设计方法、可维护性、是否进行了单元测试和代码审查等方面。在一些公司,如华为,每年都会评选优秀代码(金码奖),以表彰那些在代码编写、设计、测试等方面表现出色的开发者。
绩效和职业发展
获得金码奖不仅是对个人代码水平的认可,也是对其职业能力的一种肯定,当然有了金码奖你的绩效也有了保证。在软件相关的岗位上,代码能力是衡量一个开发者水平的重要标准。
总结
综上所述,编写易于理解、遵循规范的代码对于开发者个人和团队都至关重要。它不仅关系到代码的质量和项目的可维护性,也是评估一个开发者专业水平的重要依据。

编码与设计的统一
在软件工程中,源代码不仅是实现功能的指令集,更是设计意图的具体体现。高层设计,或称为架构,涉及对系统组件及其与外部接口的整体规划,确保系统的演进能够兼容且改动最小。而低层设计,也称为详细设计,则专注于具体函数的实现逻辑和用例的编码细节。
架构师的角色
《高效程序员的45个习惯》一书强调,架构师必须参与编码,这表明架构、设计、编码和测试构成了软件开发的统一活动,它们之间不存在不可逾越的鸿沟。理想的源代码应达到这样的标准:即便没有额外文档,通过阅读代码本身也能理解其背后的业务逻辑和设计意图。这种代码的编写体现了编程的艺术性,其中函数名、类名和简单的注释足以传达程序员的意图和深思熟虑。
设计与实现的一致性
在企业实践中,设计和开发常常由不同团队负责,这引发了如何保持设计与实现一致性的问题。设计阶段的蓝图若在开发过程中发生偏移,最终产品可能会与最初的设计大相径庭。解决这一难题的关键在于强化设计与代码的一致性,确保设计和编码工作的紧密衔接。
跨界合作的重要性
架构师和设计师应当具备对代码层面的深入理解,而进行底层设计的开发者也应有对架构的清晰认识。这种跨界合作有助于产出更高质量的代码,提升系统的可维护性。每个层级的人员都应该愿意跨越职责边界,对整个系统有更全面的理解。
编码、设计与架构的融合
综上所述,编码、设计和架构相互渗透、相互影响,它们是软件开发核心的组成部分。通过打破职责界限,促进不同层级间的沟通与协作,可以显著提升软件项目的整体质量和效率。

初始阶段的代码与长期可维护性
软件开发初期,编写的代码通常能够良好地实现所需功能。但随着时间推移,未经精心维护的代码库可能会变得难以维护,甚至无法添加新功能。这种现象部分源于敏捷开发的原则,即避免过度工程化,以保持设计的简洁性,不过多预测未来的不确定性。
代码库的复杂化与重构需求
随着项目的迭代,代码库若未得到合理维护,将逐渐变得复杂和混乱。新加入的开发人员,特别是实习生或应届生,可能会发现接手的代码缺乏文档,难以理解,使得继续开发变得困难。
微重构与全面重构
面对可维护性问题,可能需要对代码库进行重构。重构分为微重构和全面重构两种:微重构是在不改变现有功能的情况下,对代码进行小规模改进,如优化函数结构、提升代码可读性;而全面重构则涉及对整个系统架构的重新设计,这通常是成本高昂且风险较大的决策。
鼓励质量与重构
企业应鼓励开发者在实现功能的同时,关注代码质量。面对庞大函数,优秀员工不仅满足于功能的简单添加,而是会主动进行微重构,提升代码的可维护性。
项目交付与重构的平衡
尽管重构对提升代码质量至关重要,但必须注意不要因此耽误项目交付时间。项目的成功交付要求高质量的输出,并遵守既定的时间节点,企业以结果为导向。
全面重构的决策
在现有架构无法支持进一步开发时,进行全面重构成为必要选择,尽管成本高昂。这对于那些追求长期发展的公司尤其重要。
一个案例!

案例分析:代码质量与公司存亡
在20世纪80年代末,一家推出了广受欢迎的“杀手级应用”的公司,随着时间的推移,却逐渐遭遇了发展的瓶颈。尽管产品初期受到许多专业人士的青睐,但随后产品发布周期开始延长,软件缺陷难以得到及时修复,加载时间变长,系统崩溃的频率也在增加。这些技术问题最终导致了用户体验的大幅下降,使得用户不得不放弃使用该软件。不久之后,该公司也宣告倒闭。
多年后,当询问该公司的一位早期雇员关于公司倒闭的原因时,他的回答揭示了一个令人警醒的事实。原来,公司在急于推出产品的过程中,编写了大量混乱的代码。随着功能的不断增加,代码质量持续下降,最终达到了无法维护的地步。正是这些糟糕的代码导致了公司的失败,这一案例强调了代码质量对于公司长期成功的重要性。
软件开发中,代码的不断膨胀是一个常见现象。需求的不断增长导致功能的不断增加,而每次迭代往往由不同的开发人员完成,这很容易导致代码质量的下降。理论上,如果有一位技术高手持续维护整个代码库,问题可能不会发生。然而,在现实中,由于员工的离职和交接,以及不同开发人员能力和理念的差异,代码质量的维护变得充满挑战。
企业文化和员工能力也是影响软件质量的重要因素。以谷歌为例,其员工不仅技术能力强,而且公司文化也鼓励高质量的工作成果。这使得进入谷歌工作成为许多专业人士的梦想,同时也反映了公司对员工能力和文化重视的程度。
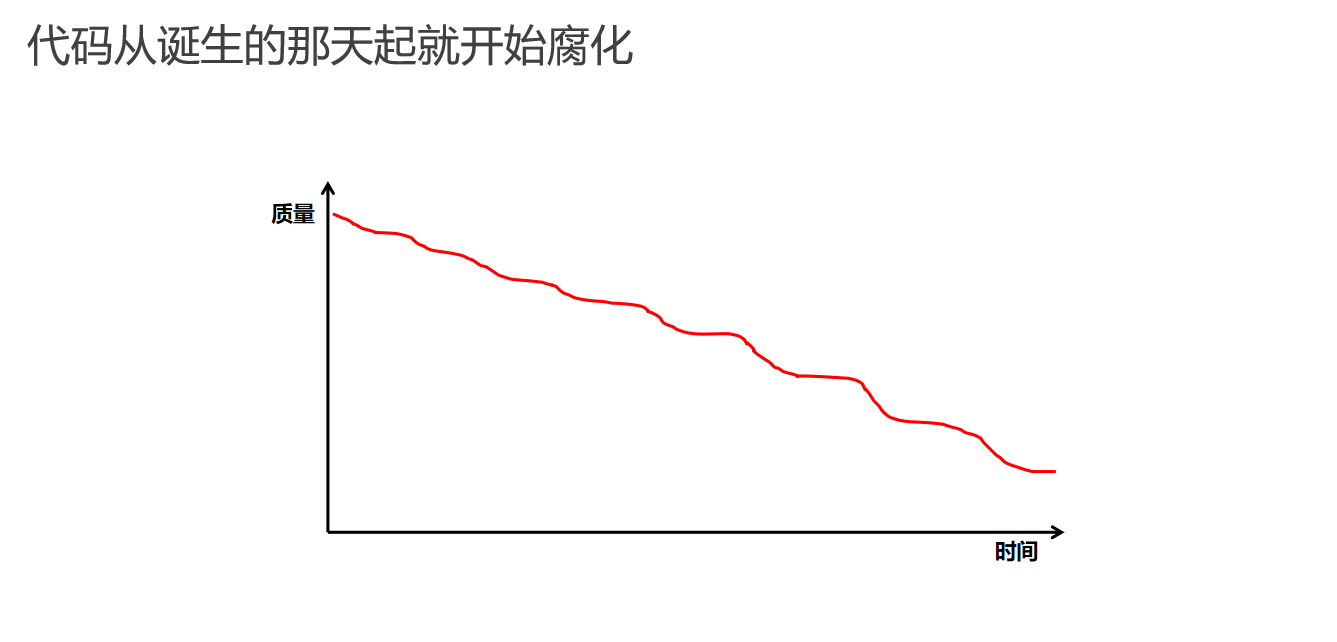
代码质量的退化与测试的重要性
软件开发过程中,代码的质量和可维护性是随着时间的推移而逐渐退化的。这种现象几乎是不可避免的,因为随着功能的不断增加,代码库会变得越来越复杂,导致维护难度增加。这种复杂性的增长,如果没有得到有效的控制和管理,最终会导致软件质量的下降。
在软件开发中,测试是一个关键环节,但往往不被足够重视。如果测试环节得不到充分的投入和关注,软件的可测性也会随之下降。在没有足够测试用例的情况下,我们甚至可能不清楚应该测试什么,以及如何确保软件的各个部分都经过了充分的测试。
理论上,每段代码都应有相应的测试用例,以确保其正确性和稳定性。然而,在实际操作中,由于资源、时间或技术限制,我们很难做到对每一行代码都进行详尽的测试。这导致软件中存在未被发现的错误和漏洞,随着时间的推移,这些问题会逐渐累积,加剧软件的腐化。
代码的逻辑复杂性增加,加之缺乏清晰的业务理解和文档支持,使得后来的开发者难以理解现有代码的业务含义和设计意图。这种理解上的断层,使得维护和更新变得更加困难,最终可能导致软件无法继续满足用户的需求。
因此,为了应对代码质量的退化,软件开发团队需要采取一系列措施,包括但不限于:
- 持续集成和持续部署(CI/CD):通过自动化测试和快速迭代,尽早发现和修复问题。
- 代码审查:确保代码质量,促进团队成员之间的知识共享。
- 技术债务管理:识别和优先处理那些影响软件质量和可维护性的技术债务。
- 文档编写:提供充分的文档支持,帮助新团队成员快速理解现有系统。
- 业务和技术培训:提升团队对业务需求和技术实现的理解。
通过这些措施,可以减缓代码质量退化的速度,提高软件的可维护性和可测试性,从而延长软件的生命周期。

版本轮回与软件重构的困境
在软件开发的某个阶段,开发团队可能会面临一个令人不满的现实:他们所依赖的代码基础变得难以继续开发。这种代码的恶化往往导致开发周期延长,缺陷难以修复,性能下降,最终使得开发团队向管理层提出彻底重构的请求。
管理层虽然不愿意投入资源进行彻底的重构,但他们也不得不承认当前的生产力已经低到了不可接受的水平。最终,管理层可能会同意开发团队的要求,批准进行全新的设计。这时,会组建一个新的团队,这个团队被视为充满希望的“白纸”,他们有机会从头开始,创造出真正优雅和高效的系统。
然而,这样的新团队通常只吸纳最优秀和最聪明的成员,而其他成员则继续维护和更新现有的系统。这导致了两个团队之间的竞争:新团队需要构建一个能够实现旧系统所有功能的全新系统,并跟上旧系统的持续改动。只有在新系统的功能足以匹敌或超越旧系统时,管理层才会考虑替换旧系统。这种竞赛可能会持续很长时间,有时甚至超过十年。而当新系统最终完成时,最初的团队成员可能已经离开,现有成员也可能因为系统的质量问题而再次要求进行重构。
这种版本轮回的现象在企业中并不罕见。管理层往往面临着来自产品和市场的压力,要求不断增加新功能,却很少提供足够的时间和资源来进行必要的系统优化。这种短视的策略可能会导致开发团队的士气下降,产品质量的恶化,以及长期的维护问题。
客户和利益相关者也可能会担心软件的长期可维护性。特别是对于那些关键基础设施和服务的运营商,如大型银行、国家电网或中国电信、中国移动等,他们对系统的稳定性和可靠性有着极高的要求。任何系统故障或性能下降都可能带来严重的后果。

代码作为“债务”的隐喻
在软件开发领域,存在着一种观点,即将代码视为一种“债务”而非资产。这种观点认为,尽管初始编写的代码可以迅速转化为产品并创造收益,但随着时间的推移,代码的维护成本会逐渐增加,从而成为团队的负担。
随着代码量的增加,添加新功能的难度和成本也会随之上升。代码的混乱和复杂性不仅使得新功能的集成变得更加困难,而且也增加了维护和修复缺陷的工作量。这种现象最终会导致开发团队的效率下降,即使投入更多的人力资源,产出的代码量和质量却可能不增反降。
软件界的一个普遍真理是,你拥有的代码越多,添加新内容所要付出的成本就越高。更糟糕的是,如果代码维护不当,其混乱程度会随着时间推移而加剧,进一步增加未来的开发成本。
Craig Larman 曾提出,“最好维护的代码就是没有代码”,这句话强调了减少代码量以提高软件质量的重要性。优秀的程序员会通过重构和优化现有代码,减少代码的冗余和复杂性,从而提高功能集成的效率。他们的“代码产量”可能是负的,因为他们通过减少代码量来增加功能,这样做可以降低长期的维护成本。
在实际的软件开发过程中,团队应该设定目标,减少代码量,同时增加软件的功能和性能。例如,一个团队可能会挑战自己,不仅要交付一定数量的新功能,还要通过优化和重构减少一定量的代码。这样的目标有助于推动团队专注于代码质量,而不是单纯的代码数量。
度量和监控代码量是管理软件“债务”的重要手段。团队应该定期评估现有代码的健康状况,并采取措施减少不必要的复杂性和冗余。通过这种方式,团队可以避免代码量的无序增长,确保软件的长期可持续发展。

代码的可读性:为人编写,而非机器
软件开发中有一个核心理念,即代码的编写应首先考虑人类读者的理解能力。正如Martin Fowler所言,“任何一个傻瓜都能写出机器能懂的代码,但好的程序员应该写出人能懂的代码”。这句话强调了代码的可读性对于其他程序员的重要性。
进一步地,有观点认为程序的编写“是给人看的,附带能在机器上运行”,以及“编写程序首先为人,其次为计算机”,这些观点都出自业内的知名人士,如Steve McConnell。这些原则突出了代码的可交流性和可维护性,而不仅仅是它的功能性。
代码的可读性是编程的基础。机器执行代码的能力并不会因为代码的复杂或混乱而受阻,但人类理解和维护代码的能力却会受到显著影响。因此,编写清晰、结构良好的代码对于团队合作和项目的长期成功至关重要。
此外,一个常见的现象是,即使是代码的原始作者也可能在一段时间后难以理解自己的代码。如果原始作者在一个月后回头看自己的代码时感到困惑,那么其他开发者在接手这些代码时所面临的挑战就更大了。
因此,良好的编程实践不仅仅是为了写出机器可以执行的代码,更重要的是要写出其他开发者能够轻松理解的代码。这包括使用清晰的命名约定、编写有意义的注释、保持代码的逻辑简洁以及遵循一致的编码标准。
最终,这种以人为中心的编程理念有助于提升团队的效率,降低维护成本,并确保软件项目的持续发展和成功。

代码可读性与维护性
在软件开发中,代码的可读性对于维护和迭代至关重要。编写新代码的时间相对较少,而阅读和理解现有代码则占据了大部分时间。据估计,阅读与编写代码的时间比例可能高达10:1。因此,提高代码的可读性对于提升工作效率至关重要,即便这可能在一定程度上增加编写代码时的难度。
在团队中,开发者往往不是从头开始创建全新的功能,而是在现有产品的基础上进行迭代、维护和二次开发。这些工作都建立在对现有代码的深入理解之上。如果对现有代码的理解不准确,那么新增的功能也可能会出现问题。
因此,开发者在编写代码时,应考虑到未来可能需要阅读和维护这些代码的其他同事。良好的代码不仅功能正确,而且易于理解,这可以显著减少维护成本,并且体现了对团队和项目的责任感。
团队文化应该鼓励开发者写出既满足功能需求又易于维护的代码。这种文化导向有助于提升团队的整体绩效,并简化长期的维护工作。
同时,开发者应当避免过度注释。虽然注释可以帮助解释代码逻辑,但代码本身应当具有足够的自解释能力。过多的注释可能会分散阅读者的注意力,降低代码的可读性。注释应当简洁明了,用于补充代码未能清晰表达的逻辑。
最终,开发者应当培养一种换位思考的习惯,想象未来的维护者将要阅读和理解这些代码,这有助于提升代码的整体质量,减少未来可能出现的维护问题。

为未来维护者编写代码
编程时,我们应该始终铭记,未来的某个时刻,别人将接手我们的工作。因此,为将来维护代码的人着想,不仅是职业操守的体现,也是确保项目长期成功的关键。
道德和能力的评价
有一句话形象地说明了这一点:“编程的时候,总是想着那个维护你代码的人会是一个知道你住在哪儿的有暴力倾向的精神病患者。” 这句话虽然带有幽默色彩,但它强调了写出易于理解和维护的代码的重要性。
同样,一个程序员的道德和能力,很大程度上可以通过他离开后,接手工作的同事的评价来衡量。这种评价往往比管理层的看法更为准确和有参考价值。
换位思考提升代码质量
在实际工作中,开发者应该避免编写那些让人难以理解的代码。我们应该努力避免写出那些让人一看就想抱怨的代码。相反,我们应该追求写出那些即使在多年后,也能让维护者轻松理解、维护和扩展的代码。
技术领导者的选择
此外,技术领导者的选择也很重要。许多互联网公司的管理者,尤其是技术领导者,往往从技术能力较强的员工中选拔。这是因为,只有深入了解技术细节的人,才能更好地理解开发过程中的挑战和需求。
纯管理背景的人员可能更关注交付和进度,而忽视了代码的质量。这种短视的管理方式不利于项目的长期发展,尤其是在大型公司中,这种管理思维是不可持续的。

代码的可理解性:最重要的指导原则
代码的编写应当遵循一个核心原则——易于理解。这一原则的重要性基于一个事实:在软件开发过程中,阅读和理解现有代码的时间远远超过编写新代码的时间。因此,我们的目标是最小化他人理解代码所需的时间。
时间与资源的分配
尽管开发者可能经常加班,包括周末,但实际上用于编写新代码的时间非常有限。对于新员工而言,初入职的半年可能是学习和编写代码的时间相对较多,但随着时间的推移,可用时间可能会减少。
代码的自我修养
代码的可理解性不仅仅体现在具体的编程技巧上,它还反映了程序员的专业修养。一个程序员的自我修养在很大程度上可以通过其编写的代码是否易于他人理解来体现。
命名的重要性
在追求代码可理解性的过程中,命名是一个关键的细分领域。良好的命名能够大大增强代码的可读性,使得代码的意图和功能一目了然。虽然易于理解的概念可能比较抽象,但通过遵循一系列具体的编程原则和实践,可以显著提升代码的质量。
命名

编程中的命名规范
在编程领域,良好的命名习惯对于提升代码的可读性和可维护性至关重要。变量名、函数名、参数名、类名以及文件目录名等,都需要遵循一定的规范和逻辑。
变量名应直观反映其代表的数据含义,函数名应清晰描述其执行的操作,参数名则应准确传达其作为输入或输出的角色。类名通常采用大驼峰命名法,以体现其实体性和封装的特性。文件和目录的命名则应体现其内容的组织结构,便于开发者快速定位和浏览。
大型企业,如华为,通常会制定一套内部的编码规范,这些规范不仅包括命名规则,还可能涵盖代码格式、注释风格等其他方面。这些规范有助于保持代码的一致性,提高团队协作的效率。
现代的集成开发环境(IDE)和代码编辑器,例如VS Code,提供了对编码规范的检查功能。这些工具可以帮助开发者自动检测和修正不符合规范的命名,从而减少人为错误,提高代码质量。

名副其实:编程中的变量命名
在编程中,变量命名应遵循“名副其实”的原则,即名称应清楚地表达变量的用途和它所代表的值。例如,使用 elapsedTimeInDays 比单独的 ind 更能直观地传达变量代表的是“消逝的时间,以日计”。如果一个变量名需要注释来辅助理解,那么这个命名就不够直观。
选择好的变量名需要时间
选择一个好的变量名确实需要花费时间,但这是一项值得投资的工作,因为它能够为整个开发团队节省更多的时间。在华为等公司,我们了解到,代码的可读性是首要考虑的因素。变量的名称可以长一些,关键是要有意义,能够让人读懂。
避免不明确的缩写
避免使用不明确的缩写,如 ETD,除非它们是广泛认可的标准缩写。长变量名没有问题,但要确保它们不会变得过于冗长,从而影响代码的整洁性。
面试中的观察
在面试过程中,我注意到许多候选人倾向于使用单个字母来命名变量,这可能是出于节省时间的考虑。然而,这种做法并不理想,因为它牺牲了代码的可读性。
变量命名的平衡点
正确的做法是首先确保变量名能够让人理解,然后再考虑名称的长度。总之,变量命名应该清晰、具体,避免使用不明确的缩写,同时在可读性和简洁性之间找到平衡点。这样做可以提高代码的可维护性,促进团队间的有效沟通。
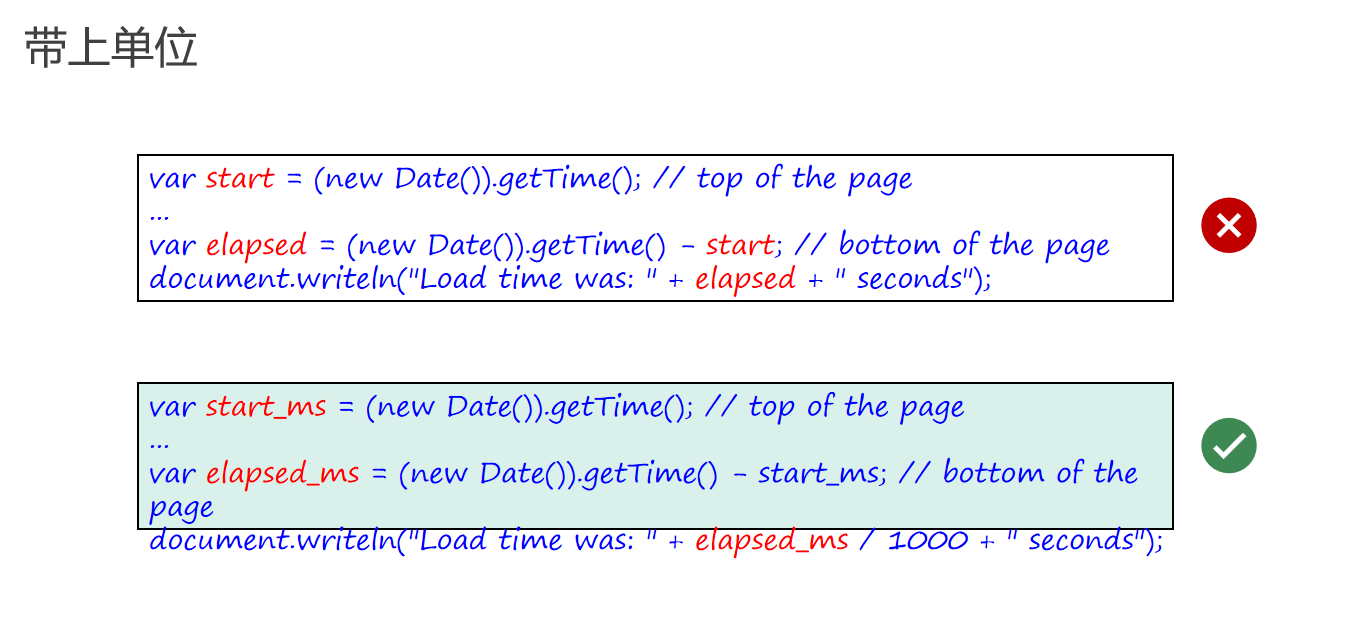
命名应体现单位和上下文
在编程中,变量的命名不仅要传达其代表的数据含义,还应体现其单位和上下文。这样做可以减少代码阅读时的歧义,提高代码的可维护性。
缺少单位信息的问题
开发者有时会忽略在变量名中包含单位信息,这可能导致在使用变量时出现误解。例如,一个表示时间的变量如果没有明确其单位是毫秒,那么在使用该变量进行计算时,可能需要额外的单位转换,这增加了出错的风险。
上下文信息的重要性
良好的命名还应该能够提供足够的上下文信息,使得其他开发者能够快速理解变量的用途。如果变量名中包含了其单位或相关的业务逻辑信息,那么即使没有额外的注释或文档,代码的意图也能一目了然。
避免不必要的猜测
当代码中使用了不明确的单位或缺乏上下文信息时,其他开发者可能需要花费额外的时间去理解代码的具体实现。这不仅降低了工作效率,也增加了引入错误的可能性。

如何使用缩写
在编程中,缩写的使用应当谨慎,并且遵循一定的标准。一个重要的评判标准是,团队的新成员是否能够理解缩写的含义。
通用的缩写示例
以下是一些通用的、广泛认可的缩写示例:
- eval 代表 “evaluation”(评估)
- doc 代表 “document”(文档)
- str 代表 “string”(字符串)
避免创造新的缩写
如果缩写不是广泛认知的,或者不是行业内的标准缩写,那么最好避免使用。例如,如果你创造了一个由几个单词组成的缩写,而这个缩写并不是大家普遍认知的,那么最好不要使用它。
缩写的广泛意义
只有当缩写具有广泛的意义,并且团队成员普遍了解其含义时,缩写才是合适的。这样可以确保代码的可读性,避免造成误解。
个人建议:谨慎使用缩写
建议,个人在编写代码时应谨慎使用缩写。最好不要使用缩写,因为不是所有人都能理解缩写的具体含义。编写代码时,应该从阅读代码的角度出发,确保代码对所有团队成员都是清晰和易于理解的。
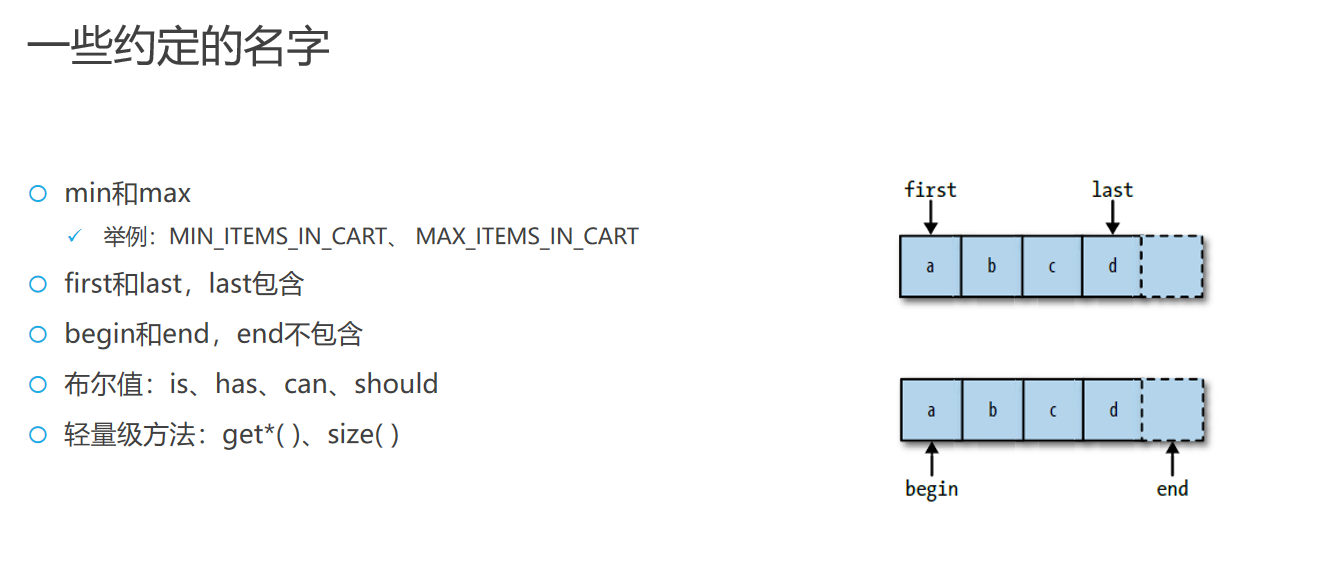
编程中的约定命名
在编程实践中,一些特定的命名约定被广泛接受和使用,这些约定有助于提高代码的可读性和一致性。
使用min和max
min 和 max 常用于表示最小值和最大值。例如,MIN_ITEMS_IN_CART 和 MAX_ITEMS_IN_CART 分别用来表示购物车中商品数量的最小和最大限制。
first和last的使用
first 和 last 通常用于指向序列的开始和结束。需要注意的是,last 在某些情况下可能不包含序列的最后一个元素,这类似于编程中的闭区间和半开区间的概念。
begin和end
begin 和 end 也用于表示序列的开始和结束,通常 end 不包含在序列中,即它是序列的后一个位置。
布尔值命名
布尔值的命名应具有明确的业务含义,推荐使用 is、has、can、should 等前缀,如 isEnabled 或 hasAccess。这样的命名能够清楚地表明布尔值的用途。
轻量级方法命名
对于返回信息而不改变对象状态的轻量级方法,常用的命名模式是 get*(),如 getName()。此外,对于返回集合大小的方法,通常使用 size()。
避免使用否定形式
在命名布尔值时,应尽量避免使用否定形式,如 isNotEnabled,因为这可能会造成理解上的混淆。相反,应该使用肯定形式的命名,如 isEnabled。
注释
注释的重要性与平衡
在编写代码时,注释是必不可少的,但同时也不应过度依赖注释。理想的做法是使代码尽可能自我解释,即通过清晰的命名和逻辑结构来传达其意图,减少对注释的依赖。
避免不写注释和过度注释
不写注释可能会导致代码难以理解,特别是当代码逻辑复杂或涉及特定业务规则时。另一方面,过度注释可能会使代码阅读者感到困惑,尤其是当注释内容显而易见或冗余时。
代码的自我解释能力
努力使代码自我注释意味着要通过变量命名、函数设计和逻辑结构来传达代码的目的和工作方式。这样做可以提高代码的可读性和可维护性。
静态检查工具的局限性
现有的静态检查工具和自动化工具通常无法完全评估注释的质量。注释是否适当,往往需要人工审查来确定。这是因为注释的内容往往与业务逻辑紧密相关,而业务逻辑的复杂性通常超出了自动化工具的识别能力。
人工审查的必要性
人工审查是确保代码质量的重要环节,特别是在评估注释是否恰当、代码是否易于理解方面。虽然自动化工具可以检查代码的语法和一些潜在的错误,但它们无法完全取代人类对于代码意图和逻辑的判断。
设计模式和业务逻辑
在应用设计模式和处理复杂业务逻辑时,自动化工具的作用有限。这些情况通常需要开发者具备深厚的专业知识和经验,以及通过人工审查来确保代码的正确性和可维护性。
总结
在编程中,注释应简洁而有力,帮助解释代码背后的逻辑和业务规则。同时,开发者应追求代码的自我解释能力,并通过人工审查来确保代码的整体质量。
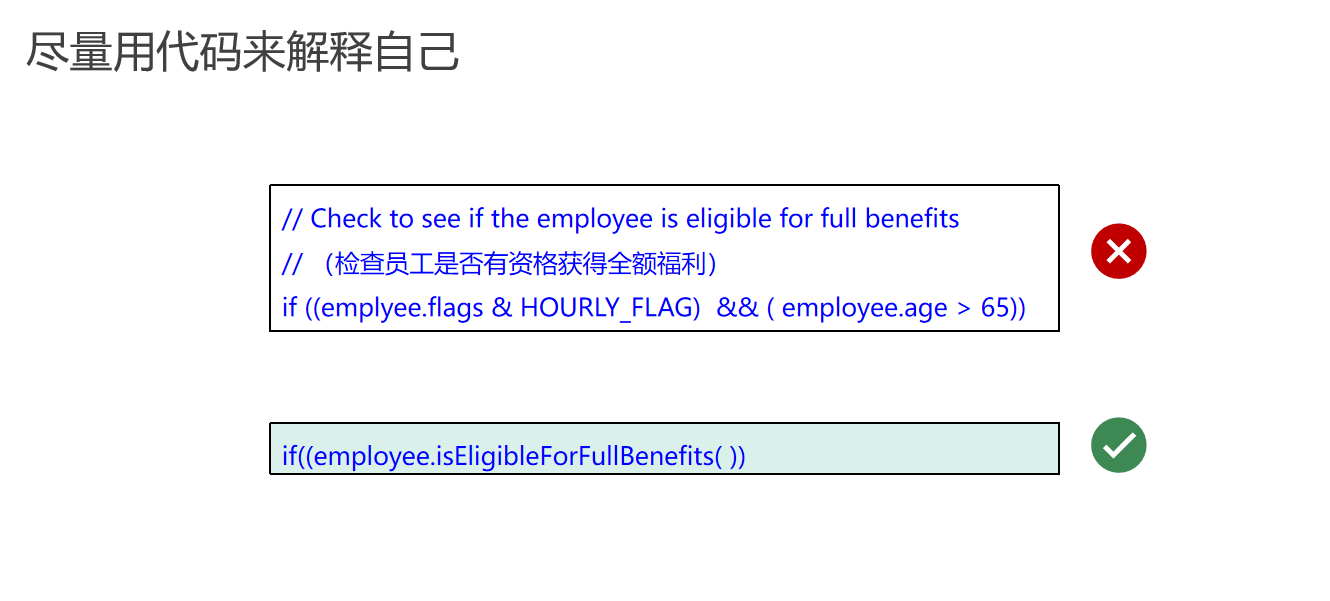
用代码自我解释
在编程中,注释的使用是一个需要谨慎对待的话题。一方面,注释能够帮助解释代码的功能和上下文,但另一方面,过度依赖注释而不是通过清晰的代码来表达意图,可能会导致代码的可读性降低。
避免不必要的注释
韩鹏提到,许多开发者在初学编程时往往不愿意写注释,更倾向于编写代码本身。随着经验的积累,一些开发者可能会开始过度注释代码,这同样不是一个好的实践。关键的原则是,如果代码已经足够清晰地表达了其意图,那么注释就是多余的。
代码的自我解释能力
优秀的代码应该能够自我解释。例如,使用 isEligibleForFullBenefits() 这样的布尔方法来检查员工是否符合条件,比使用复杂的条件语句和标志位更清晰。这样的方法命名直接传达了其功能,减少了对注释的依赖。
何时使用注释
尽管如此,注释在某些情况下是必要的。当代码背后有特定的业务逻辑或前提条件时,注释可以用来提供额外的上下文信息。这些信息可能对于理解代码的整体逻辑至关重要,尤其是当代码在未来需要维护或更新时。
注释的最佳实践
注释应该用来补充那些无法通过代码本身表达的信息,如领导的特定要求或临时的业务决策。在这些情况下,注释不仅帮助解释代码,还能够提供代码变更的历史记录。
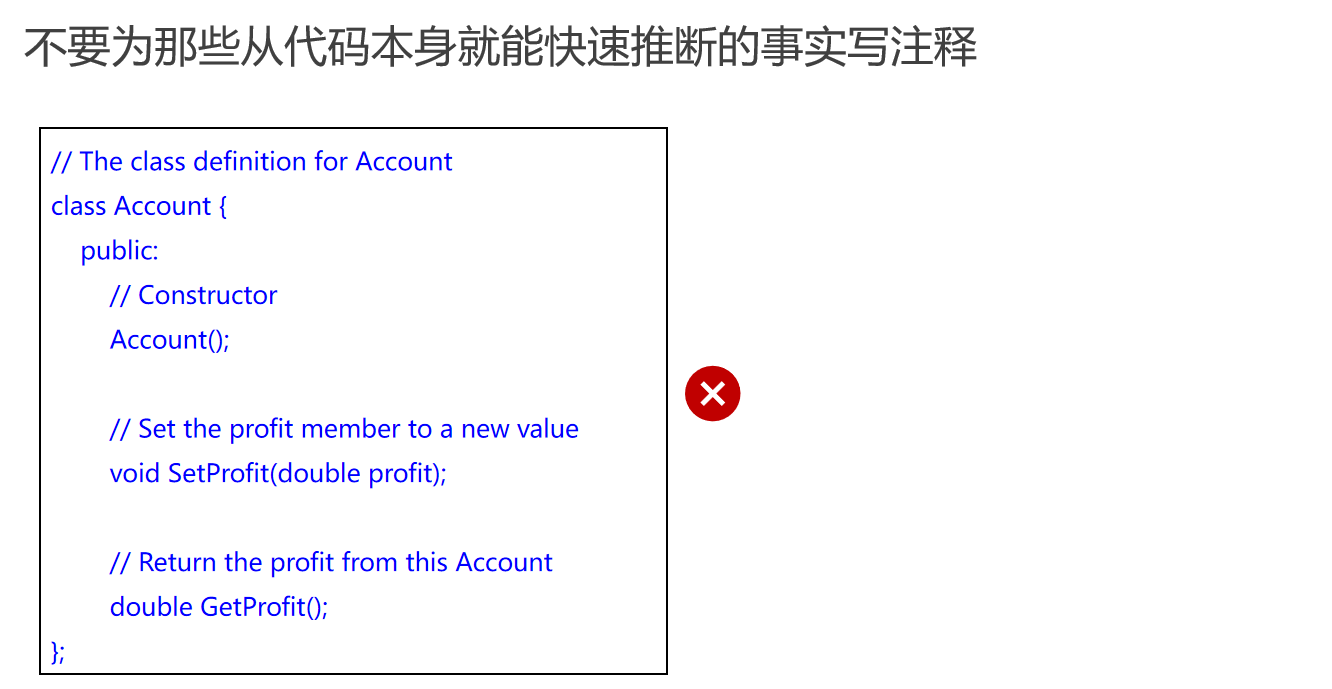
避免冗余注释
编程时,注释应提供额外的上下文或解释代码背后的逻辑,而不是复述显而易见的代码功能。例如,对于简单的类定义或构造函数,额外的注释通常是不必要的。
class Account {
public:
Account(); // 构造函数
void SetProfit(double profit); // 设置账户的利润值
double GetProfit(); // 获取账户的利润值
};
注释的适度
应当避免过度注释,即对已经清晰的代码进行不必要的说明。如果注释比代码本身还长,或者对显而易见的代码进行解释,那么注释就失去了其价值。
注释的风格和规范
注释的风格应当遵循团队或组织的编码规范。例如,类的注释通常不需要用双线分隔,这可能不符合某些团队的注释规范。注释应当简洁明了,提供对代码的补充说明,而不是重复代码已经表达的内容。
何时使用注释
注释应当用于以下情况:
- 解释代码背后的业务逻辑或决策原因。
- 描述函数的预期行为、参数的含义以及返回值的类型。
- 记录代码的作者、创建时间和修改历史,尤其是当代码逻辑复杂或有特定的维护要求时。

好代码的定义
好代码不仅仅是功能正确,它还应该易于理解、维护和扩展。一个简单的标准是,好代码应当在没有注释的情况下也能让人理解其意图和功能。
注释与代码的关系
有时候,即使代码本身看起来是中规中矩的,如果它需要大量的注释来解释,那么这可能意味着代码本身并不足够清晰。理想情况下,代码的结构和命名应该足够直观,使得额外的注释成为非必须。
避免不必要的注释
在以下示例中,DeleteRegistry 函数的命名可能不够直观,需要注释来解释其实际作用是“释放key的向柄”。相比之下,ReleaseRegistryHandle 提供了更清晰的信息,即使没有注释,也能理解其意图。
复制
// 坏代码的例子,需要注释来解释其行为
void DeleteRegistry(RegistryKey* key);
// 好代码的例子,即使没有注释也能理解其行为
void ReleaseRegistryHandle(RegistryKey* key);

实例的重要性
在解释复杂的编程规则或函数行为时,长篇的描述可能不如一个简单的例子来得直观和易于理解。例子可以清晰地展示输入和预期的输出,使得读者能够快速把握函数的功能。
例子胜过长描述
在某些情况下,即使提供了详细的规则说明,如果没有具体的例子,读者可能仍然难以完全理解。相反,一个恰当的例子可以简化理解过程,帮助读者快速掌握概念。
代码示例的清晰表达
在函数或方法的注释中,提供一个或多个例子可以展示如何使用该函数,以及它在特定情况下的行为。这种方式可以避免冗长的解释,直接通过实例来阐明代码的意图。
复制
/**
* 去除字符串中的指定前缀和后缀。
*
* 示例:Strip("abba/a/ba", "ab") 返回 "/a/"
*
* @param src 要处理的原始字符串。
* @param chars 要去除的字符集合。
* @return 处理后的字符串。
*/
String Strip(String src, String chars) { ... }
格式

代码表达的清晰性
在阅读代码时,清晰的表达方式可以显著提高理解效率。例如,对比两种不同的代码表达方式,一种可能让读者感到费劲,而另一种则更为直观易懂。
代码结构的相似性
在函数或方法的实现中,如果存在结构相似的代码块,应该考虑是否有可能通过重构来提高代码的复用性。机器检查工具可以检测代码的相似度,如果发现有高度相似的代码段,这可能表明存在代码复用的机会。
代码复用的考量
在企业开发中,代码复用是一种推崇的做法,因为它可以减少重复劳动,提高代码的可维护性。然而,在考试或编程竞赛中,如果提交的代码相似度过高,可能会被认定为抄袭,尤其是在缺乏适当的引用或解释时。
代码的个性化
即使是解决相同问题的代码,不同的开发者也会写出风格和细节上有所区别的代码。这是因为每个人的编程习惯、思维方式以及实现细节都有所不同。
面试中对代码相似度的看法
在技术面试中,面试官可能会对高度相似的代码表示关注,并询问其来源。如果候选人无法提供合理的解释,这可能会影响他们的面试结果。

代码格式与组织的重要性
在编程过程中,良好的代码格式和组织方式对于提升代码的可读性和维护性至关重要。以下是一些关键的格式和组织原则:
段落与空行 代码应该按照逻辑功能进行分段,每个段落或函数通过空行清晰地分隔开,以便于理解每个部分的作用。
避免过长的代码段 如果一个段落或函数过长,没有空行分隔,通常意味着该部分代码过于复杂,需要进一步拆分。
注释的使用 适当地使用注释,尤其是对于较长的代码段,可以极大地提高代码的可读性。注释应简洁明了,说明代码的功能和目的。
自动化格式化工具 现代的集成开发环境(IDE)提供了自动化的代码格式化工具,这些工具可以帮助我们按照既定的编码标准来格式化代码,提高代码的一致性和可读性。
核心原则:可读性 编写代码时应遵循一个核心原则——让其他开发者能够轻松阅读和理解。如果代码全部堆砌在一起,没有适当的分隔和注释,那么它将难以阅读和维护。
循环和逻辑
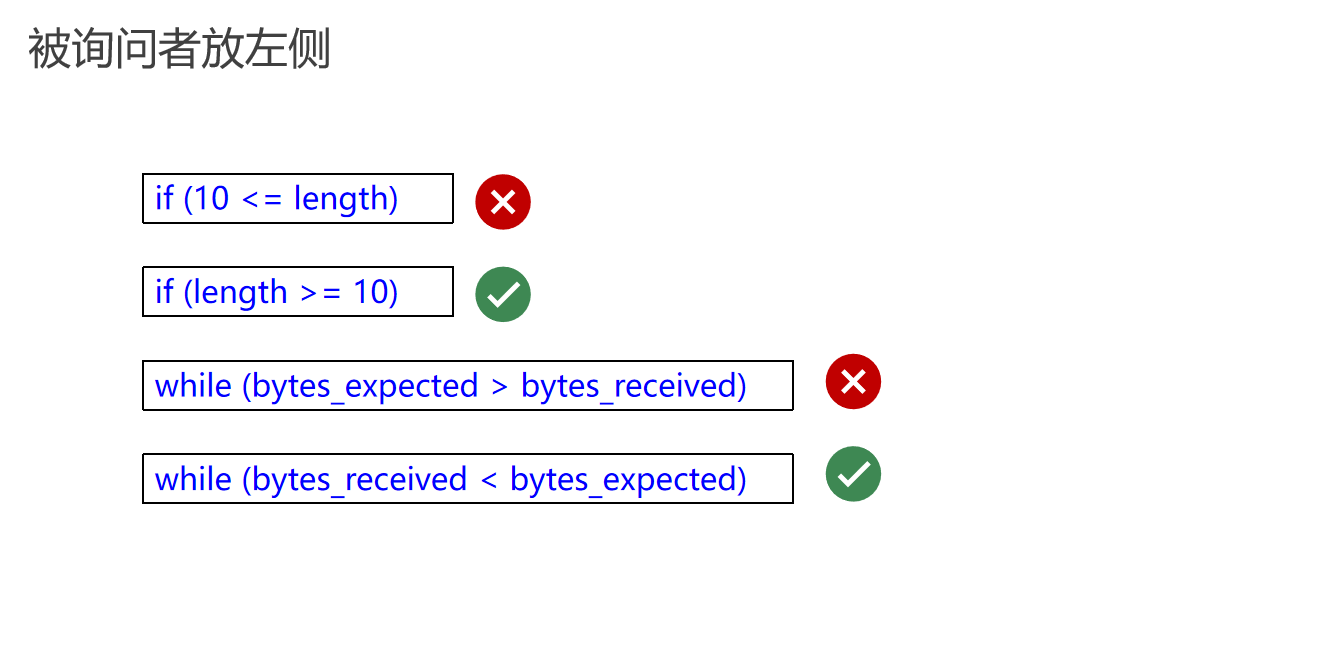
编程中条件语句的可读性
在编程中,条件语句的写法对于代码的可读性和理解性至关重要。以下是一些关于如何提高条件语句可读性的建议:
-
变量位置
将被判断的变量放在条件语句的左侧,这样可以使代码更加直观易懂。例如,使用 if (length > 10) 而不是 if (10 < length)。 -
避免复杂的转换
尽量避免在条件语句中进行复杂的思维转换。直接表达条件,使得读者可以快速理解代码的意图。 -
使用直观的比较
使用更直观的比较方式,如 while (bytesReceived != bytesExpected),而不是 while (bytesReceived == bytesExpected),以减少读者理解所需的转换。 -
强调主语
在条件语句中强调主语,即被判断的对象。例如,将 if (expectedBytes > receivedBytes) 改为 if (receivedBytes < expectedBytes),将焦点放在主动接收的变量上。 -
符合写作习惯
遵循社区和团队的编码习惯。如果存在广泛接受的规范,最好遵循这些规范,以保持代码风格的一致性。 -
减少错误的可能性
在某些复杂的场景下,将被判断的变量放在前面可以减少出错的可能性,因为这样可以减少阅读和理解所需的认知负担。
示例对比
以下是一个简单的示例,展示了不同写法对可读性的影响:
不推荐:
if (10 < length)
while (bytesReceived == bytesExpected)
推荐:
if (length > 10)
while (bytesReceived != bytesExpected)
在编程实践中,选择哪种写法取决于具体的上下文和团队的编码标准。然而,通常推荐使用更直观、更容易理解的表达方式,以提高代码的可读性和维护性。

正确使用三目运算符的示例
timeStr += (hour > 12) ? "pm" : "am";
在这个例子中,三目运算符用于一个简单的条件判断,即如果 hour 大于 12,则 timeStr 追加 “pm”,否则追加 “am”。这是一种合适的三目运算符使用场景,因为它简洁且易于理解。
避免在简单逻辑中使用 if-else 的示例
if (hour > 12) {
timeStr += "pm";
} else {
timeStr += "am";
}
尽管上述代码是正确的,但在这种情况下使用 if-else 语句会显得不必要地冗长,因为它可以用更简洁的三目运算符替代。
复杂逻辑中避免使用三目运算符的示例
return exponent >= 0 ? mantissa * (1 < exponent) : mantissa / (1 < -exponent);
这个表达式试图处理更复杂的逻辑,但由于涉及多步运算,使用三目运算符会使得代码难以阅读和维护。此外,该表达式中还包含了语法错误。
更合适的做法
对于复杂的逻辑判断,建议使用 if-else 语句,如下所示:
if (exponent >= 0) {
return mantissa * (1 << exponent);
} else {
return mantissa / (1 << -exponent);
}
这种方式提高了代码的可读性和可维护性,并且当逻辑变得更加复杂时,更易于调试和理解。
三目运算符在C语言中非常有用,但它最适合用于简单的条件判断。在逻辑较为复杂或涉及多步运算的情况下,使用 if-else 语句是更好的选择。
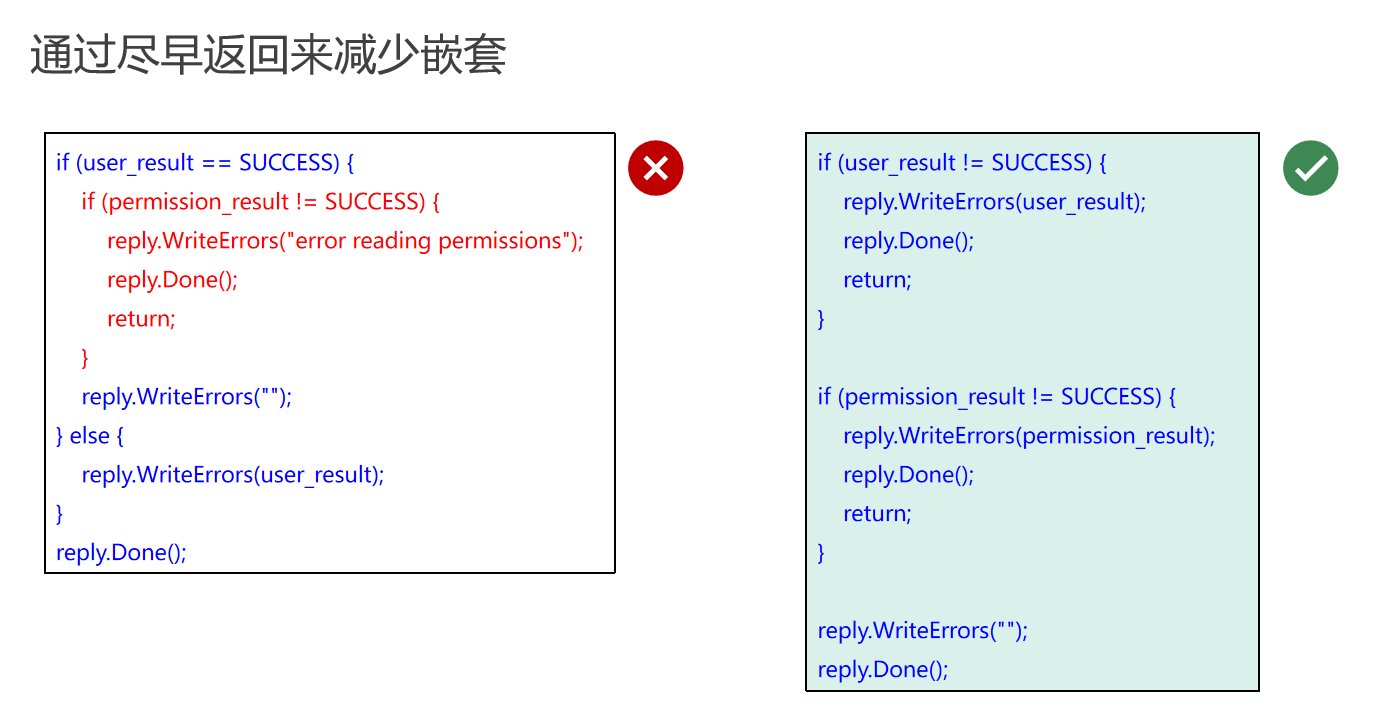
通过尽早返回来减少嵌套
在编程中,减少代码嵌套可以提高代码的可读性和可维护性。以下是一个通过尽早返回来减少嵌套的示例:
if (userResult == SUCCESS) {
if (permissionResult != SUCCESS) {
reply.WriteErrors("error reading permissions");
reply.Done();
return;
}
reply.WriteErrors("");
} else {
reply.WriteErrors(userResult);
reply.Done();
return;
}
优化前的代码示例
if (userResult == SUCCESS) {
if (userResult != SUCCESS) { // 这里的逻辑是错误的,应为 permissionResult
// ... 错误处理逻辑
}
reply.WriteErrors("");
if (permissionResult != SUCCESS) {
// ... 错误处理逻辑
} else {
// ... 其他逻辑
}
reply.Done();
return;
}
reply.WriteErrors("");
reply.Done();
优化后的代码示例
if (userResult != SUCCESS) {
reply.WriteErrors(userResult);
reply.Done();
return;
}
if (permissionResult != SUCCESS) {
reply.WriteErrors("error reading permissions");
reply.Done();
return;
}
// ... 其他逻辑
reply.WriteErrors("");
reply.Done();
时间复杂度的考量
在编程中,减少 if、else 和循环语句的使用可以降低时间复杂度。每个额外的 if 或循环都可能增加代码的复杂性。理想情况下,一个函数中的 if 或循环语句的数量应保持在有限的范围内,通常不超过五个。
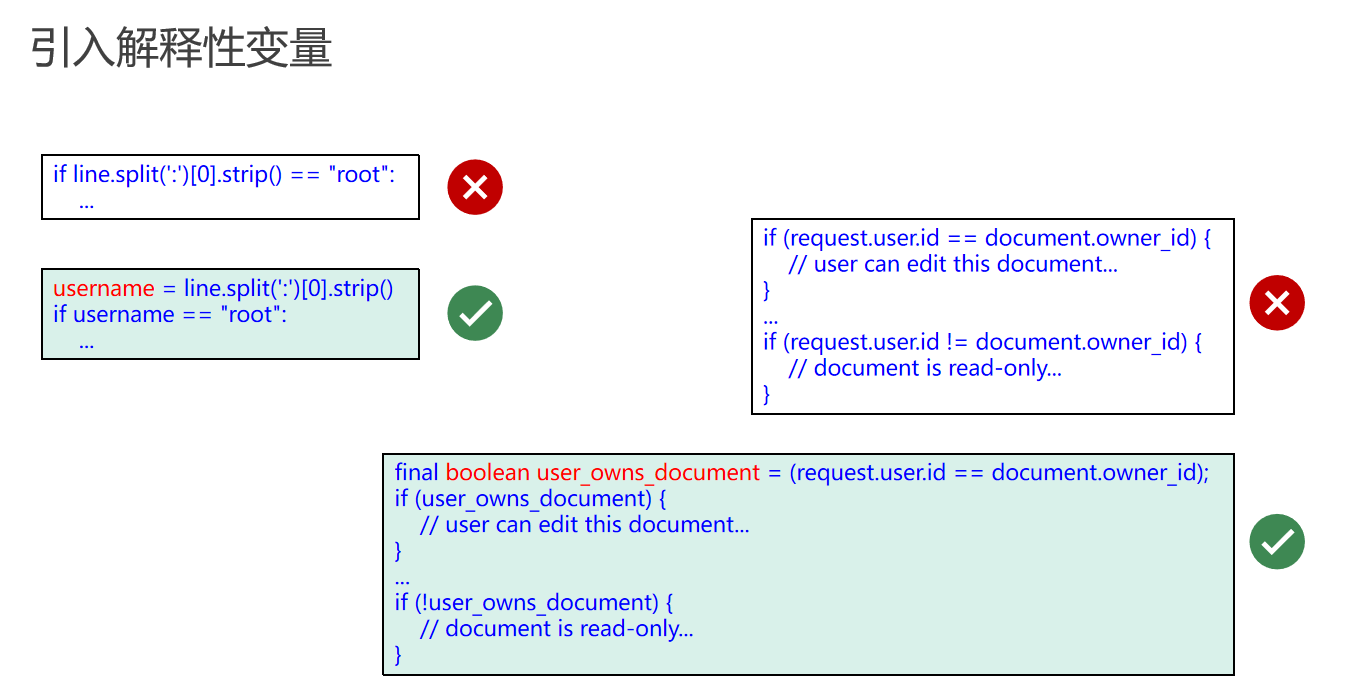
引入解释性变量以提高代码可读性
在编程中,引入解释性变量可以显著提高代码的可读性和清晰度。以下是一些示例和建议:
- 避免复杂的直接判断
不要直接在条件语句中使用复杂的表达式,这样会增加代码的理解难度。
// 避免的写法
if (line.split(":")[0].strip() == "root") {
// ...
}
- 引入变量简化条件判断
通过引入一个解释性变量来简化条件判断,使得代码更加清晰易懂。
// 推荐的写法
String username = line.split(":")[0].strip();
boolean isRootUser = "root".equals(username);
if (isRootUser) {
// ...
}
- 描述业务逻辑的变量
使用布尔型变量来描述业务逻辑,避免在条件判断中直接使用业务逻辑表达式。
// 推荐的写法
boolean userOwnsDocument = request.user.id == document.ownerId;
if (userOwnsDocument) {
// User can edit the document...
} else {
// Document is read-only...
}

句子的解释
- He never had no faith in nobody
- 这句话的意思是“他从未对任何人有过信任”。
- 我不得不否认,你不是个笨蛋
- 这句话的意思是“我必须承认,你不是个笨蛋”,等同于“我不认为你是个笨蛋”。
- 我倒不觉得他们最后决定不告诉你这件事并不是没有一点道理
- 这句话的意思是“我认为他们最终决定不告诉你这件事是有他们的道理的”。
- 我不是不肯不让你知道我不是不爱你的
- 这句话的意思是“我不是不愿意让你知道我是爱你的”,等同于“我确实愿意让你知道我是爱你的”。
处理这类句子时,可以将它们转换成更直接和清晰的表达方式,以避免逻辑上的混淆。在编程中,这意味着要确保逻辑表达式正确地反映了句子的意图。
例如,如果我们将第一句翻译成代码中的一个条件表达式,可能会是:
bool hasFaith = true; // 假设有一个变量表示是否信任某人
bool neverHadFaith = !hasFaith; // 使用否定来表示“从未有过信任”
在处理这类否定句时,重要的是要仔细分析句子的结构和意图,确保逻辑表达式与句子的本意相符
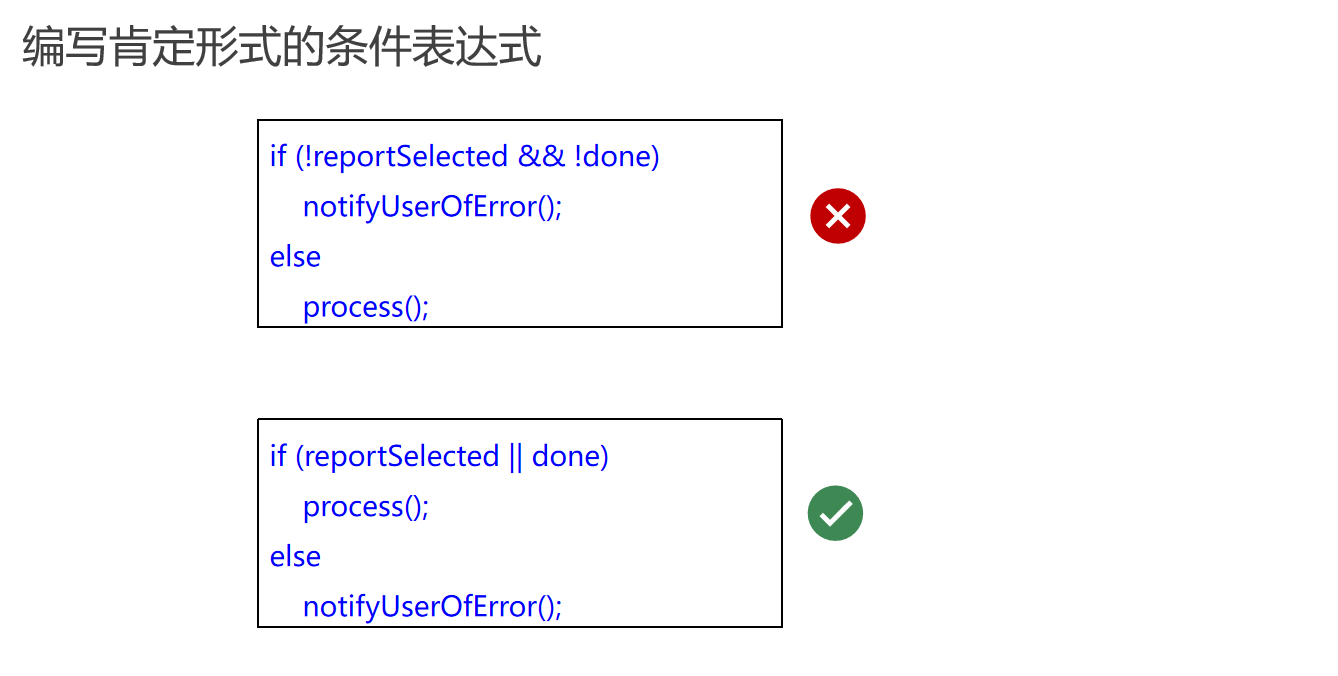
避免使用否定逻辑
在编程中,否定逻辑可能会导致代码难以理解和维护。以下是如何将否定逻辑转换为肯定逻辑的示例:
原始的否定形式条件表达式
复制
if (!reportSelected && !done) {
notifyUserOfError();
} else {
process();
}
在这个例子中,逻辑是“如果 reportSelected 不是所选的,且 done 不是完成的,则通知用户错误;否则,执行 process”。
转换为肯定形式的条件表达式
if (reportSelected || done) {
process();
} else {
notifyUserOfError();
}
在这个重写的版本中,我们避免了否定逻辑,直接表达了“如果 reportSelected 是所选的,或 done 是完成的,则执行 process;否则,通知用户错误”。


优化代码逻辑和减少时间复杂度
在编程中,优化代码逻辑和减少时间复杂度是提高程序效率的重要方面。以下是如何优化代码以避免不必要的变量声明和减少时间复杂度的示例:
原始代码示例
var remove_one = function (array, value_to_remove) {
var index_to_remove = null;
for (var i = 0; i < array.length; i += 1) {
if (array[i] === value_to_remove) {
index_to_remove = i;
break;
}
}
if (index_to_remove !== null) {
array.splice(index_to_remove, 1);
}
};
优化后的代码示例
var remove_one = function (array, value_to_remove) {
for (var i = 0; i < array.length; i += 1) {
if (array[i] === value_to_remove) {
array.splice(i, 1);
return;
}
}
};
在这个重写的版本中,我们直接在找到匹配元素时从数组中移除它,避免了声明额外的变量 index_to_remove,并且减少了代码的复杂度。
讨论
- 避免不必要的变量
在原始代码中,index_to_remove 用于存储找到的索引,但这不是必要的。优化后的代码直接在找到元素时进行移除。 - 减少时间复杂度
原始代码中,如果找到了匹配的元素,程序会在执行一次额外的循环来移除元素。优化后的代码在找到元素后立即移除并退出函数,减少了不必要的迭代。 - 一次性写好代码
尽量在编写时就写出高效、简洁的代码,避免在后期重构时花费更多的时间。

缩小变量作用域的最佳实践
在编程中,缩小变量作用域是一个重要的实践,它有助于提高代码的清晰度和安全性。以下是一些相关的建议和示例:
- 避免全局变量
尽量不要使用全局变量,因为它们可以在程序的任何地方被访问和修改,这可能导致不可预见的副作用。 - 局部变量的使用
将变量定义在它们被需要的作用域内。这样做可以减少变量在不相关代码中的可见性,从而降低出错的风险。 - 按需定义变量
在代码中第一次使用变量的地方定义它们。这有助于读者快速定位变量的用途和生命周期。 - 通过参数传递
如果一个变量需要在多个方法间共享,考虑将其作为参数传递,而不是使用全局变量。
代码示例对比
使用全局变量的示例
class LargeClass {
string str_;
void Method1() {
str_ = ...; // 定义全局变量
Method2();
}
void Method2() {
// Uses str_
}
// 其他许多方法可能会使用 str_
};
优化后使用局部变量的示例
class LargeClass {
void Method1() {
string str = ...; // 定义局部变量
Method2(str);
}
void Method2(string str) {
// Uses str
}
// 现在其他方法不能看到 str,作用域得到缩小
};

变量定义紧靠使用原则
在编程中,将变量的定义放置在其使用位置的附近是一种良好的实践。这样做可以减少代码的复杂性,提高代码的可读性,并使得变量的作用域尽可能小。
原始代码示例
def ViewFilteredReplies(original_id):
filtered_replies = []
root_message = Messages.objects.get(original_id)
all_replies = Messages.objects.select(root_id=original_id)
root_message.view_count += 1
root_message.last_view_time = datetime.datetime.now()
root_message.save()
for reply in all_replies:
if reply.spam_votes <= MAX_SPAM_VOTES:
filtered_replies.append(reply)
return filtered_replies
优化后的代码示例
def ViewFilteredReplies(original_id):
root_message = Messages.objects.get(original_id)
root_message.view_count += 1
root_message.last_view_time = datetime.datetime.now()
root_message.save()
all_replies = Messages.objects.select(root_id=original_id)
filtered_replies = []
for reply in all_replies:
if reply.spam_votes <= MAX_SPAM_VOTES:
filtered_replies.append(reply)
return filtered_replies
讨论
- 缩小作用域
通过将 all_replies 和 filtered_replies 的定义移动到它们被使用之前,我们减少了这些变量的作用域,使得它们只在需要的代码块中可见。 - 提高可读性
优化后的代码更加清晰地展示了程序的执行流程,读者可以更容易地理解变量的使用目的和上下文。 - 避免过早定义
避免在代码的开始部分定义所有变量,而是应该在它们即将被使用之前进行定义。
设计函数

函数设计的首要原则
在编程中,设计函数时应遵循一些基本原则以提高代码的可读性、可维护性和效率。以下是一些关键的函数设计原则:
- 短小精悍
函数应该尽量短小,完成一个单一的任务。这是函数设计的首要原则。 - 单一职责
每个函数应该只负责一个功能点,如果功能过于复杂,应该将其分解为多个函数。 - 避免重复
如果发现函数中存在重复的代码,应该考虑重构以消除重复。 - 定义靠近使用
变量的定义应该尽量靠近其使用的位置,以减少作用域并提高可读性。 - 减少复杂度
避免编写过于复杂的函数,如果逻辑复杂,应该将其分解为更简单的部分。
代码示例对比
原始函数示例
def ViewFilteredReplies(original_id):
# ... 省略中间代码 ...
for reply in all_replies:
if reply.spam_votes <= MAX_SPAM_VOTES:
filtered_replies.append(reply)
return filtered_replies
优化后的函数示例
def is_spam(reply):
return reply.spam_votes <= MAX_SPAM_VOTES
def filter_replies(all_replies):
return [reply for reply in all_replies if is_spam(reply)]
def ViewFilteredReplies(original_id):
root_message = Messages.objects.get(original_id)
# ... 省略其他代码 ...
all_replies = Messages.objects.select(root_id=original_id)
filtered_replies = filter_replies(all_replies)
return filtered_replies

用函数降低复杂度
创建函数的一个关键原因是为了降低程序的复杂度。通过将大问题分解为小的、可管理的部分,我们可以更容易地理解和解决这些问题。正如Edsger Dijkstra所指出的,认识到我们大脑容量的局限性,我们应该谦卑地处理编程任务,通过创建子程序来隐藏实现细节,从而简化问题。
在编程实践中,这意味着我们应该:
- 隐藏实现细节:函数可以封装特定的功能,使得调用者不必关心内部实现。
- 提高可读性:通过将复杂逻辑分解为独立的函数,代码结构更清晰,易于理解。
- 增强可维护性:小的、单一职责的函数便于定位和修改,有助于降低维护成本。
- 促进代码复用:良好的函数设计可以使得函数在不同场景下被复用,避免重复。
以字符串处理为例,如果函数需要处理两个字符串,并且逻辑较为复杂,我们可以通过创建子函数来分别处理插入、删除和修改等操作。这样,主函数就只负责调用这些子函数,而每个子函数则专注于处理一种特定的操作。
例如,对于判断两个字符串是否可以通过一次编辑操作变得相同的问题,我们可以这样设计:
def can_transform(str1, str2):
# 检查两个字符串长度的差异
if abs(len(str1) - len(str2)) > 1:
return False
# 创建两个指针,分别指向两个字符串的起始位置
i, j = 0, 0
while i < len(str1) and j < len(str2):
if str1[i] != str2[j]:
# 如果字符不同,根据字符串长度决定是插入还是删除操作
if len(str1) < len(str2):
j += 1
else:
i += 1
else:
i += 1
j += 1
return True
在这个例子中,我们首先检查两个字符串长度的差异,然后通过两个指针逐一比较字符。如果遇到不同的字符,根据字符串长度决定是进行插入还是删除操作。这样的设计使得函数逻辑清晰,易于理解和维护。

圈复杂度的概念和重要性
圈复杂度(Cyclomatic Complexity)是一种衡量程序源代码复杂度的指标,由Thomas J. McCabe在1976年提出。它通过计算程序中不同的执行路径数量来度量方法的复杂性。
- 度量方法
圈复杂度是基于程序中独立路径的数量来计算的,这些路径通过程序中的决策点(如if语句、循环等)来区分。 - 建议标准
McCabe建议,为了保持代码的可维护性,圈复杂度最好不要超过10,某些特殊情况下也最好不要超过15。
实际编程中的应用
在实际编程中,圈复杂度的概念被用来指导函数的设计,确保每个函数尽可能简洁且功能单一。
- 降低复杂度
通过将复杂逻辑分解为多个简单函数,可以降低单个函数的圈复杂度。 - 代码评审
在一些组织中,如华为,圈复杂度是代码评审的重要标准之一。代码的圈复杂度如果过高,可能会导致代码评审不通过。 - 影响晋升和评奖
在某些公司,软件编码能力的考核,包括圈复杂度的遵守,可能会影响到员工的晋升和评奖。 - 维护现有代码
对于老代码,即使圈复杂度较高,如果没有重构的计划,也应该避免进一步增加其复杂度。 - 特殊情况处理
如果确实无法降低圈复杂度,可以通过专门的评审流程,由专家团队评估并决定是否可以接受当前的复杂度。
结论
圈复杂度是衡量代码复杂性和可维护性的重要指标。程序员应该努力降低自己代码的圈复杂度,以提高代码质量和长期可维护性。在一些组织中,遵循圈复杂度的指导原则是代码评审和职业发展的关键因素。

计算函数的圈复杂度
圈复杂度是一种衡量程序源代码路径复杂度的指标,其计算规则如下:
- 基础值
从1开始计数。 - 决策点
遇到每个 if、while、for 或 case 语句时,圈复杂度加1。 - 逻辑运算符
对于 &&(逻辑与)或 ||(逻辑或),如果它们用于控制流程(如在 if 语句中),每个运算符会增加圈复杂度的计数。 - 案例语句
在 switch 语句中,每种 case 情况都会使圈复杂度加1。
示例代码的圈复杂度计算
考虑以下代码片段:
if(((status == SUCCESS) && done) || (!done && (numLines > maxLines))) {
// 业务代码
}
根据上述规则,该代码片段的圈复杂度计算如下:
- 基础值:1
- if 语句:增加1
- 第一个 &&:增加1,因为它引入了一个新的条件分支。
- 第二个 &&:虽然是在第一个 && 的内部,但同样增加了新的条件分支,因此也增加1。
- ||:增加1,因为它连接了两个独立的条件分支。
因此,该代码片段的圈复杂度为 5。
降低圈复杂度的策略
- 抽取函数
当函数过于复杂时,可以通过抽取子函数来降低复杂度。 - 优化业务逻辑
重新设计业务逻辑,以减少决策点和条件逻辑的数量。 - 避免否定逻辑
尽量使用肯定逻辑,避免使用否定词,这有助于减少逻辑错误并提高代码的清晰度。 - 利用IDE
现代集成开发环境(IDE)可以辅助编写更规范的代码,提高编码效率。

圈复杂度与软件风险
圈复杂度是衡量代码逻辑复杂性的一个指标,它直接关联到代码的可维护性和出错风险。
- 风险增加
圈复杂度过高意味着逻辑分支多,这可能导致开发者难以全面理解所有执行路径,增加了出错的风险。 - 测试难度
当圈复杂度较高时,编写测试用例来覆盖所有可能的执行路径变得更加困难,这可能导致测试不全面,难以发现潜在的缺陷。
控制圈复杂度的标准
不同的工具和组织可能会有不同的圈复杂度控制标准。以下是一些常见的分类:
- 低复杂度
1-4:表示方法逻辑简单,风险较低。 - 中等复杂度
5-7:表示方法逻辑适中,需要适度关注。 - 高复杂度
8-10:表示方法逻辑复杂,存在较高风险。 - 非常高的复杂度
11+:表示方法逻辑非常复杂,风险很大,需要重构以降低复杂度。
工具检查标准
自动化工具,如SonarQube,可以帮助开发者检测和管理圈复杂度。这些工具通常提供了检查标准,以帮助团队维持代码质量。

其它类型的复杂度度量
除了圈复杂度,还有其他几个重要的度量指标,用于评估代码的复杂性和可维护性:
- 代码行数
通常对单个文件的行数有限制,例如不超过2000行,以保持文件的可管理性。 - 函数行数
对函数的行数也有限制,有的要求不超过30行,有的不超过50行,以保持函数的简洁性。 - 函数参数个数
建议函数参数个数不超过五个,最好控制在三个以内,以减少参数的复杂性。 - 控制结构中的嵌套层数
嵌套层数应尽量控制在五层以内,个人建议不超过两层,以避免逻辑过于复杂。 - 函数变量数
如果函数较短小,变量数量通常不是问题,但过多的变量会降低代码的可读性。 - 同一变量的先后引用之间的代码行数(跨度)
变量的引用跨度应该尽量小,以便于理解和维护。 - 变量生存的代码行数
变量在使用过程中跨越的代码行数应尽量短,以减少理解变量作用域的难度。
实际编程中的建议
- 保持短小
尽量保持文件和函数的短小,避免代码过于冗长。 - 减少参数
如果参数过多,考虑使用对象或结构体来封装相关参数。 - 避免深层嵌套
深层嵌套的逻辑难以理解,应尽量避免。 - 限制变量数量
在函数中使用尽量少的变量,以简化逻辑。 - 合理作用域
确保变量的作用域尽可能小,以减少潜在的错误。

函数参数个数的整洁之道
在《代码整洁之道》一书中,Robert C. Martin提出了关于函数参数个数的观点,强调参数数量应当尽可能少:
- 无参数
最理想的情况是函数不需要任何参数,可以通过类的状态或其他方式获取所需的信息。 - 单参数
如果函数必须接受参数,那么一个参数通常是首选,它表明函数执行一个单一、清晰的任务。 - 双参数
在某些情况下,两个参数可能是必要的,但应当谨慎使用,以保持函数的简洁性。 - 多于三个参数
使用三个以上的参数应当有充分的理由,并且尽量避免。如果出现这种情况,可能意味着需要重构函数或者使用其他方式传递参数集。
减少参数个数的策略
- 参数对象
如果多个参数总是一起出现,可以考虑将它们封装到一个对象中,从而减少参数的数量。 - 返回值
使用函数返回值来传递信息,而不是通过输出参数。 - 全局状态
在某些情况下,使用全局状态可以消除对参数的需求,但这种做法应当谨慎,因为它可能会降低代码的可测试性。 - 工厂函数
使用工厂函数来创建返回对象的实例,而不是通过构造函数接受多个参数。
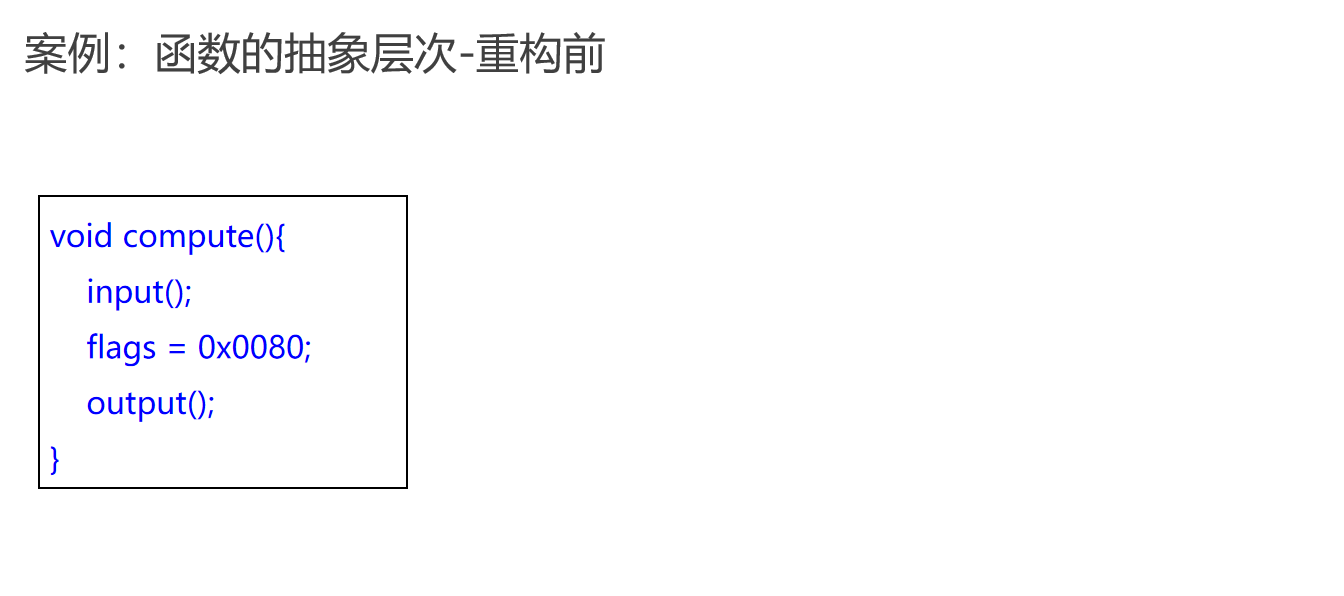


函数的抽象层次
在编程中,函数的抽象层次应该保持一致,这有助于代码的理解和维护。以下是重构前后的代码对比:
重构前的代码
void compute(){
input();
flags = 0x0080;
output();
}
在这个例子中,compute 函数执行了输入、设置标志和输出三个操作,但这些操作的抽象层次并不一致,导致代码的流畅性受损。
重构后的代码
void compute(){
input();
process();
output();
}
void process(){
flags = 0x0080;
}
重构后的代码通过引入 process 函数提高了抽象层次的一致性。现在每个函数都有明确的职责,且抽象层次保持一致,使得代码更加流畅和易于理解。
抽象层次的流畅性
- 易于理解
流畅的代码通常意味着其抽象层次保持一致,遵循从高层次到低层次的逻辑顺序。 - 避免跳跃
代码的抽象层次跳跃会使得理解和维护变得困难,应该避免。

单一抽象层次原则
单一抽象层次原则(SLAP)指出,一个函数中的所有操作都应该是同一抽象层次的。这意味着函数中的代码应该具有一致的抽象级别,避免在单个函数中混合不同层次的细节。

单一职责原则
单一职责原则(SRP)强调一个函数应该只做一件事,并做好这件事。如果函数承担了多个职责,那么当需求变化时,它可能需要在多个方向上同时修改。
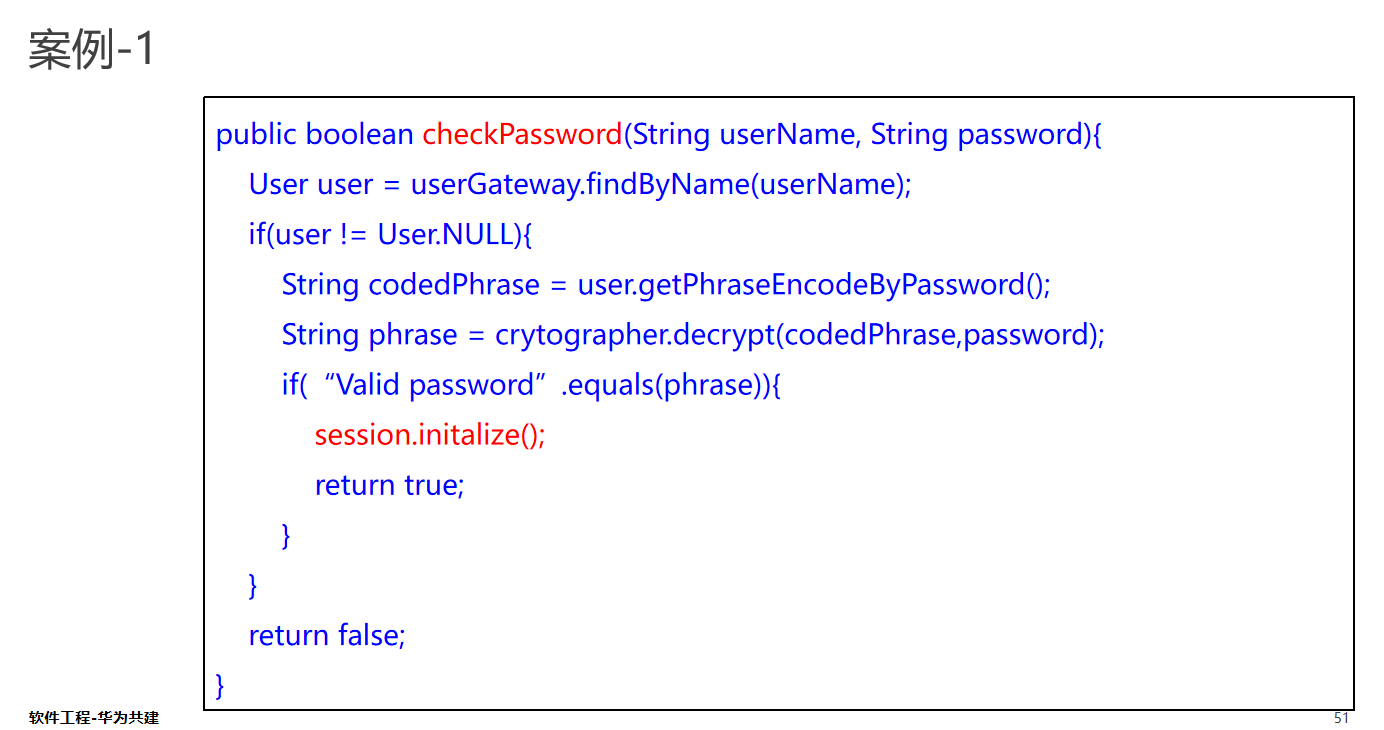
案例一分析
重构前的 checkPassword 函数执行了多个操作,包括用户查找、密码验证和会话初始化。这些操作涉及不同的抽象层次,违反了SLAP。
案例一重构后
public boolean checkPassword(String userName, String password) {
User user = findUserByName(userName);
if (user != null && user.validatePassword(password)) {
initializeSession(user);
return true;
}
return false;
}
private User findUserByName(String userName) {
return userGateway.findByName(userName);
}
private boolean validatePassword(User user, String password) {
String codedPhrase = user.getPhraseEncodeByPassword();
String phrase = cryptographer.decrypt(codedPhrase, password);
return "Valid password".equals(phrase);
}
private void initializeSession(User user) {
session.initialize();
}
在这个重构后的版本中,checkPassword 函数只关注流程控制,而具体的查找用户、验证密码和初始化会话的职责被委托给其他私有函数,从而保持了单一抽象层次。

案例二分析
set 函数的调用表明它负责设置属性并返回操作结果。这个函数可能涉及属性的查找和设置,属于同一抽象层次。

命令查询职责分离(CQRS)
CQRS原则建议将命令(执行修改操作)和查询(执行数据检索操作)的行为分离到不同的函数或方法中。这种分离可以减少代码的耦合性,并提高单个函数的单一职责性。
原始代码示例
if (attributeExist("username")) {
setAttribute("username", "micheal");
// ...
}
在这个例子中,attributeExist 函数既查询了属性是否存在,又通过 setAttribute 修改了对象的状态,这违反了CQRS原则。
遵循CQRS原则的重构后代码
public void updateUsername(String username) {
if (doesAttributeExist("username")) {
setAttribute("username", username);
}
}
private boolean doesAttributeExist(String attribute) {
// 实现检查属性是否存在的逻辑
}
private void setAttribute(String attribute, String value) {
// 实现设置属性值的逻辑
}
在这个重构后的版本中,doesAttributeExist 函数负责查询操作,而 setAttribute 函数负责修改操作。updateUsername 函数则封装了整个流程,保持了单一职责。

错误的方法分析
public void add(Object element) {
if (!readOnly) {
int newSize = size + 1;
if (newSize > elements.length) {
Object[] newElements = new Object[elements.length + 10];
for (int i = 0; i < size; i++) {
newElements[i] = elements[i];
}
elements = newElements;
}
}
elements[size++] = element;
}
在这段代码中,如果列表是只读的(readOnly 为 true),则不会执行任何添加操作,这可能是一个逻辑错误,因为添加操作应该至少返回一个错误或者异常,而不是默默失败。
正确的方法分析
public void add(Object element) {
if (readOnly) {
return;
}
if (atCapacity()) {
grow();
}
addElement(element);
}
这段代码首先检查列表是否为只读,如果是,则直接返回,避免了修改。接着,它检查列表是否达到容量,如果是,则调用 grow() 方法来扩展列表的容量。最后,它通过 addElement(element) 方法添加元素,这样做的好处是将添加元素的逻辑与检查容量和扩展容量的逻辑分离,使得代码更加清晰和模块化。
规范化重写
以下是对第二个方法的规范化重写,包括添加了注释和异常处理:
public class List {
private boolean readOnly;
private Object[] elements;
private int size;
// ... 其他方法 ...
public void add(Object element) {
// 如果列表是只读的,则不允许添加元素
if (readOnly) {
throw new UnsupportedOperationException("Cannot add element to a read-only list.");
}
// 如果列表达到容量,则扩展容量
if (atCapacity()) {
grow();
}
// 添加元素到列表
addElement(element);
}
private boolean atCapacity() {
return size == elements.length;
}
private void grow() {
// 扩展数组容量的逻辑
Object[] newElements = new Object[elements.length + 10];
System.arraycopy(elements, 0, newElements, 0, size);
elements = newElements;
}
private void addElement(Object element) {
// 添加元素到列表的逻辑
elements[size++] = element;
}
}
在这个规范化版本中,我们添加了异常处理来指出只读列表不能添加元素,并且提供了两个私有方法 atCapacity() 和 grow() 来分离检查容量和扩展容量的逻辑。这样使得 add() 方法更加简洁,并且遵循单一职责原则。同时,通过使用私有方法来封装具体的实现细节,提高了代码的可维护性和可读性。



用函数隐藏变化源
通过创建函数来封装可能会变化的行为,可以减少未来维护时的复杂性。这种方法可以保护调用者免受实现细节变化的影响。
助手方法
助手方法是小型的、私有的方法,用来使公共方法的主体部分表达得更简明。它们通过隐藏细节,让主要逻辑更加关注于通过方法名表达的意图。
实际编程中的建议
- 封装变化
识别代码中可能变化的部分,并将其封装在函数中。 - 保持抽象层次一致
确保函数中的所有操作都在同一抽象层次上。 - 使用助手方法
引入助手方法来简化复杂的表达式,提高代码的可读性。 - 单一职责
确保函数只关注一个职责,减少因职责变化而引起的修改。
代码示例
以下是如何应用上述原则的示例:
public int globalNextAccount() {
return ++nodeAccount;
}
public int max(int a, int b) {
return (a > b) ? a : b;
}
public void highlight(Rectangle area) {
reverse(area);
// 其他高亮逻辑...
}
private void reverse(Rectangle area) {
// 反转区域的逻辑...
}
在这个例子中,globalNextAccount 直接返回递增后的值,封装了计数的细节。max 函数通过条件表达式清晰地表达了比较逻辑。highlight 函数调用 reverse 助手方法来执行反转操作,隐藏了这一细节,使得 highlight 可以专注于高亮显示的逻辑。
设计类

类的封装原则
类的封装是面向对象编程中的一个基本原则,它涉及隐藏对象的内部实现细节,同时只暴露必要的操作接口。
信息隐藏
- 最小化暴露
设计良好的模块会最大限度地隐藏其内部数据和实现细节,只公开必要的操作。 - 自由修改
将变量设置为私有(private)可以避免外部依赖于内部实现,允许开发者自由地修改变量的类型或实现,而不影响外部调用者。
实际编程中的建议
- 访问限制
使用访问修饰符(如 private、protected)来限制对类成员的访问。 - 公共接口
提供公共的方法来安全地访问和修改私有成员。 - 封装细节
将复杂的逻辑和数据结构封装在类内部,只通过类提供的接口与外部交互。 - 单一职责
确保类只负责一个单一的职责,避免将不相关的功能混合在一起。
代码示例
以下是如何应用类封装原则的示例:
public class Account {
private double balance; // 私有成员,隐藏实现细节
public Account(double initialBalance) {
this.balance = initialBalance;
}
// 公共接口,提供安全的访问
public double getBalance() {
return balance;
}
public void deposit(double amount) {
if (amount > 0) {
balance += amount;
}
}
public boolean withdraw(double amount) {
if (amount > 0 && balance >= amount) {
balance -= amount;
return true;
}
return false;
}
// 其他业务逻辑...
}
在这个例子中,balance 是一个私有成员变量,它被隐藏起来,只能通过公共方法 deposit 和 withdraw 来修改。这保护了内部实现,同时提供了一个清晰的接口。

避免直接暴露集合对象
在面向对象设计中,直接暴露集合对象(如 Set、List 等)给外部是一个不好的做法,因为它破坏了封装性,使得外部代码可以直接修改集合的状态。
错误写法
复制
public class Person {
private Set<Course> courses = new HashSet<>();
public Set<Course> getCourses() {
return courses; // 错误:直接暴露了集合对象
}
public void setCourses(Set<Course> courses) {
this.courses = courses; // 错误:允许外部直接设置整个集合
}
}
在上述代码中,getCourses 和 setCourses 方法直接暴露了 courses 集合,外部代码可以不受限制地修改这个集合。
正确写法
public class Person {
private Set<Course> courses = new HashSet<>();
public void addCourse(Course course) {
this.courses.add(course); // 正确:提供添加元素的方法
}
public void removeCourse(Course course) {
this.courses.remove(course); // 正确:提供移除元素的方法
}
// 可能还有其他与courses集合相关的方法...
}
在重构后的代码中,我们提供了 addCourse 和 removeCourse 方法来控制 courses 集合的变化,而不是直接暴露整个集合。这样,Person 类可以控制课程的添加和移除逻辑,保持了集合的封装性。


迪米特法则
迪米特法则,又称为最少知识原则,是一个简单的设计原则,它指导我们只与直接朋友(成员变量、参数、返回值等)通信,而不是与陌生人(非直接朋友的对象)通信。
错误写法
final String outputDir = ctxt.getOptions().getScratchDir().getAbsolutePath();
在这个例子中,一个对象正在访问另一个对象的内部细节,这违反了迪米特法则。
正确写法
class C {
private A a;
public void f(B b) {
this.a.setActive(); // A 是 C 的直接朋友
b.invert(); // B 是方法参数,也是直接朋友
D d = new D();
d.doSomething(); // D 是一个新创建的局部对象,是直接朋友
}
}
在这个例子中,C 类只调用了其直接朋友的方法,遵守了迪米特法则。
实际编程中的建议
- 直接朋友
只访问成员变量、方法参数或新创建的对象的方法。 - 避免间接访问
避免通过一个对象访问另一个对象的私有部分。 - 封装变化
如果需要访问的对象可能会变化,考虑使用参数或返回值来传递。 - 提高可维护性
遵守迪米特法则可以减少对象之间的耦合,提高代码的可维护性。



好莱坞法则(Tell, Don’t Ask)
好莱坞法则是一个面向对象设计原则,它建议:
- 对象应该被告知去执行操作(Tell),而不是被询问以获取信息(Ask)。
- 换句话说,对象应该提供行为(动作),而不是暴露其状态。
客户与钱包
错误写法 - 直接访问和修改钱包的状态。
// 错误写法:直接询问钱包的状态并作出决策
float payment = 2.00f;
Wallet theWallet = customer.getWallet();
if (theWallet.getTotalMoney() > payment) {
theWallet.subtractMoney(payment); // 直接修改钱包状态
} else {
// 处理余额不足的情况
}
正确写法 - 通过行为方法告知钱包执行操作,不直接询问状态。
// 正确写法:告诉钱包执行支付操作,不直接询问状态
float payment = 2.00f;
customer.makePayment(payment); // 假设 makePayment 方法内部处理逻辑
电影与打印
错误写法 - 直接询问电影的状态并执行写入操作。
// 错误写法:直接询问电影的状态并写入
public class MovieList {
private List<Movie> movies;
public void writeTo(Writer destination) throws IOException {
for (Movie movie : movies) {
destination.write(movie.getName());
// ... 其他写入操作
}
}
}
正确写法 - 通过行为方法告知电影执行写入操作。
// 正确写法:告诉电影执行写入操作
public class MovieList {
private List<Movie> movies;
public void writeTo(Writer destination) throws IOException {
for (Movie movie : movies) {
movie.writeTo(destination); // 告诉电影执行写入操作
}
}
}
public class Movie {
public void writeTo(Writer destination) throws IOException {
destination.write(this.getName());
// ... 其他写入操作
}
}
在这两个例子中,正确写法都遵循了好莱坞法则,即通过行为方法告知对象执行操作,而不是直接询问对象的状态。这种方法提高了代码的封装性,降低了对象之间的耦合度,使得代码更容易维护和扩展。
其它(编程规范、静态检查工具)

编程规范的重要性
编程规范是指导开发者编写高质量、可维护代码的一系列规则和建议。遵循编程规范可以提高代码的可读性、一致性和安全性。
前端开发规范
- 阿里前端开发规范:提供了前端开发的最佳实践和规范。
- JavaScript 规范:Airbnb 提供的 JavaScript 风格指南,是一个广泛使用的 JavaScript 编码规范。注意:提供的 Airbnb JavaScript 风格的链接似乎是一个错误链接,正确的链接应该是 Airbnb 在 GitHub 上的仓库地址,例如:https://github.com/airbnb/javascript。
- Vue.js 规范:
- Vue 2 风格指南:Vue.js 2 风格指南
- Vue 3 风格指南:Vue.js 3 风格指南
Java 开发规范
- 阿里 Java 开发手册:阿里巴巴提供的 Java 开发手册,包含了详细的 Java 编程规范。
- IntelliJ IDEA 插件:Alibaba Java Coding Guidelines 是一个 IntelliJ IDEA 插件,可以帮助开发者遵循阿里巴巴的 Java 编码规范。
企业内部规范
大企业(像华为,阿里)内部也有严格的编程规范,包括通用编码规范和安全编码规范,以确保代码的安全性和减少潜在的被攻击风险。
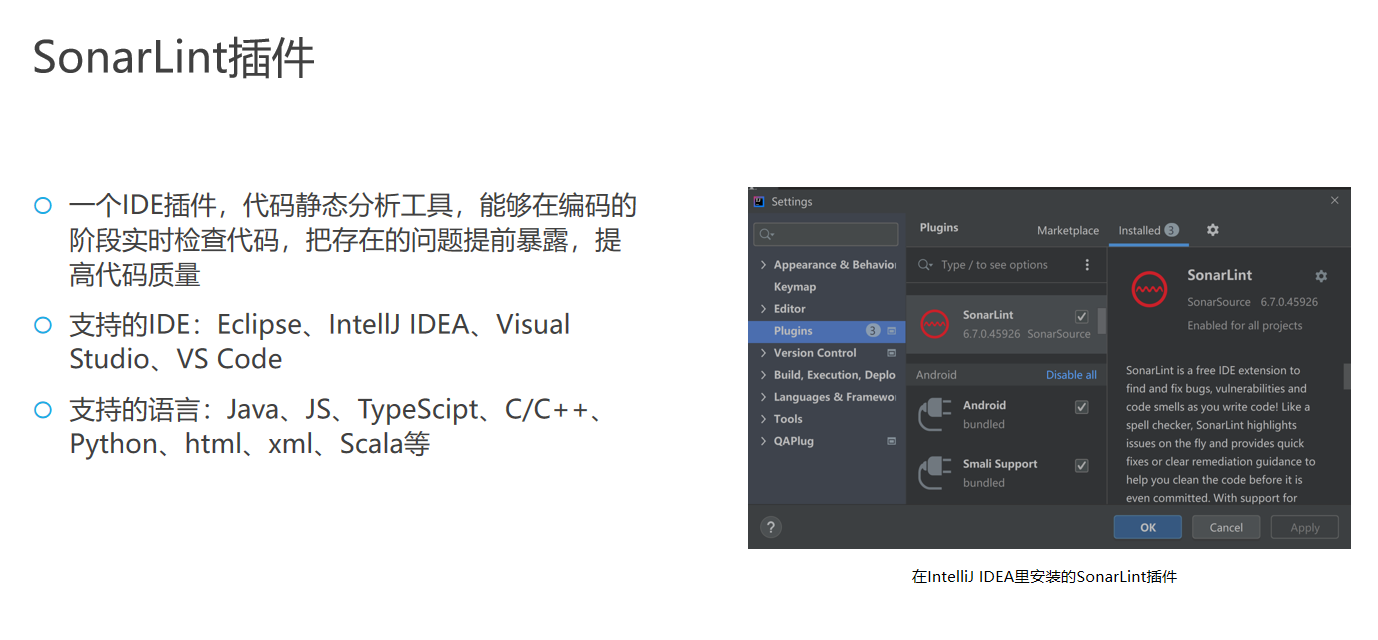
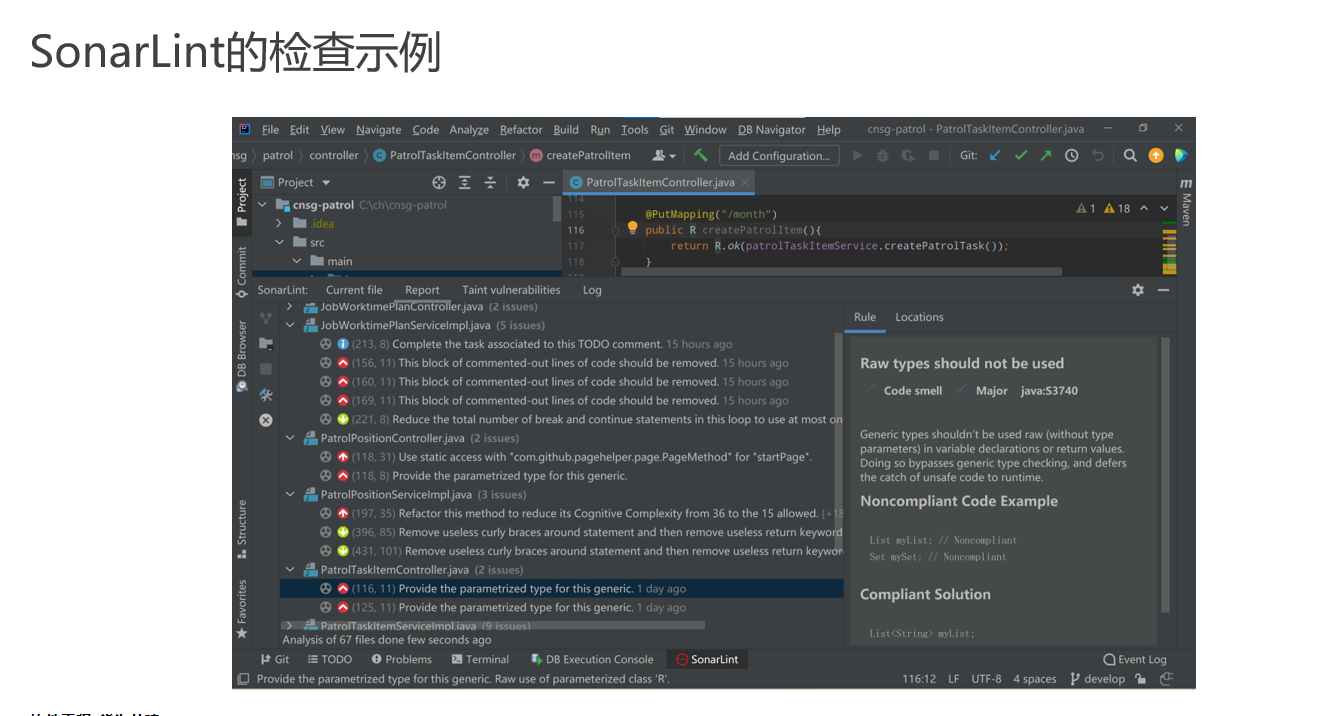
SonarLint 插件
SonarLint 是一个集成开发环境(IDE)插件,它使用静态代码分析技术来提高代码质量。该插件可以在你编写代码时即时发现潜在的缺陷、代码异味、以及可能的改进点。
重构

什么时候进行重构?
代码重构的时机
重构是软件开发中用于改进代码结构而不改变其外部行为的过程。以下是一些关于何时进行重构的建议:
- 反对专门拨出时间进行重构
重构应该是随时随地进行的活动,而不是单独分配时间的任务。 - 三次法则
第一次做某件事时,只管去做;第二次做类似的事可能会产生反感,但还是可以去做;第三次再做类似的的事时,就应该进行重构。 - 时机
- 添加功能时:在引入新功能时,如果现有代码结构不够清晰,可以进行重构。
- 修补错误时:在修复bug的过程中,如果遇到重复或糟糕的设计,可以一并重构。
- 审核代码时:在代码审核过程中,如果发现代码质量问题,可以提出重构建议。
代码的坏味道:重复代码

重复代码是代码坏味道的一种,它指的是在多个地方出现相同或非常相似的代码段。这通常意味着相同的逻辑被多次复制,增加了维护成本并可能导致错误。
原始代码示例
int GetLengthA(int n){
int l = (n * 0.1080 - 50) / 2;
printf("length %d\n", l);
if (l > 1000) {
printf("l too long\n");
return 1;
}
}
int GetLengthB(int n){
int m = (n * 0.1000 - 50) / 2;
printf("length %d", m); // 缺少结束的双引号和换行符
if (m < 500) {
printf("m too short\n");
return m;
}
}
重构后的代码示例
int calcLen(int n){
int len = (n * 0.1000 - 50) / 2; // 统一变量命名
printf("length %d\n", len); // 修正printf格式
return len;
}
int GetLengthA(int n){
int l = calcLen(n);
if (l > 1000) {
printf("l too long\n");
return 1;
}
return l; // 返回计算后的长度
}
int GetLengthB(int n){
int m = calcLen(n);
if (m < 500) {
printf("m too short\n");
return m;
}
return m; // 返回计算后的长度
}



重构是一个逐步的过程,应该在开发过程中不断进行。它要求开发者有意识地识别可以改进的代码段,并采取小步骤进行重构。重构不仅可以提升代码质量,也是提升开发者对OO思想和设计模式理解的好机会。